blog
|
May 15, 2024
Autonomous decisions: The bias-variance tradeoff in self-driving technology
Monolithic versus compound AI systems in LLMs and autonomous driving.
Prof. Amnon Shashua and Prof. Shai Shalev-Shwartz

Monolithic versus compound AI systems in LLMs and autonomous driving.
Back in November 2022, the release of ChatGPT garnered widespread attention, not only for its versatility but also for its end-to-end design. This design involved a single foundational component, the GPT 3.5 large language model, which was enhanced through both supervised learning and reinforcement learning from human feedback to support conversational tasks. This holistic approach to AI was highlighted again with the launch of Tesla’s latest FSD system, described as an end-to-end neural network that processes visual data directly “from photons to driving control decisions," without intermediary steps or “glue code."
While AI models continue to evolve, the latest generation of ChatGPT has moved away from the monolithic E2E approach. Consider the following example of a conversation with ChatGPT:
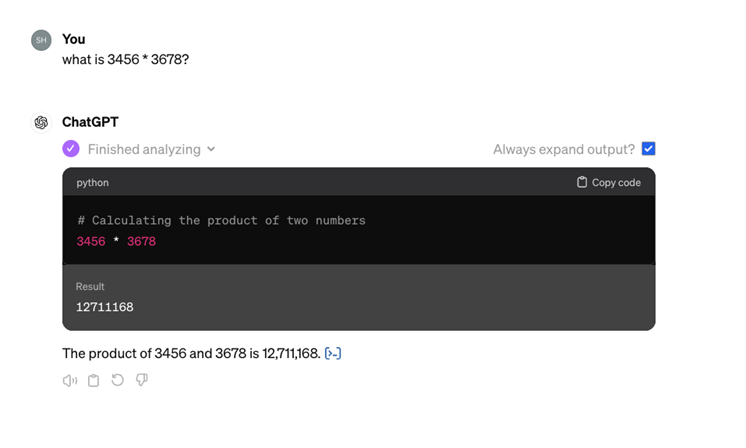
When asked to compute "what is 3456 * 3678?," the system first translates the question into a short Python script to perform the calculation, and then formats the output of the script into a coherent natural language text. This demonstrates that ChatGPT does not rely on a single, unified process. Instead, it integrates multiple subsystems—including a robust deep learning model (GPT LLM) and separately coded modules. Each subsystem has its defined role, interfaces, and development strategies, all engineered by humans. Additionally, 'glue code' is employed to facilitate communication between these subsystems. This architecture is referred to as “Compound AI Systems1” (CAIS).
Before we proceed, it is crucial to dispel misconceptions about which system architecture is "new" or "traditional". Despite the hype, the E2E approach in autonomous driving is not a novel concept; it dates back to the Alvinn project (Pomeraleau, 1989)2. The CAIS approach is also not new, but as we have shown above, it has been adopted by the most recent versions of ChatGPT.
This blog aims to explore the nuances between E2E systems and CAIS, by drawing a deep connection to the bias-variance tradeoff3 in machine learning and statistics. For concreteness, we focus the discussion on self-driving systems, but the connection is applicable more generally to the design of any AI-based system.
The bias-variance tradeoff
The grand question, driving any school of thought for building a data-driven system, is the "bias/variance" tradeoff. Bias, also known as “approximation error," means that our learning system cannot reflect the full richness of reality. Variance, also known as “generalization error," means that our learning system overfits to the observed data, and fails to generalize to unseen examples.
The total error of the learned model is the sum of the approximation and generalization errors, so in order to reach a sufficiently small error, we need to delicately control both. There is a tradeoff between the two terms since we can decrease the generalization error by restricting the learned model to come from a specific family of models, but this might introduce a bias if the chosen family of models cannot reflect the full richness of reality.
Based on this background, we can formalize the two approaches for building a self-driving system. A CAIS, or an “engineered system," deliberately puts architectural restrictions on the self-driving system for the sake of reducing the generalization error. This introduces some bias. For example, going from "photons" to a “sensing state," which is a model of reality surrounding the host vehicle—location and measurements of road users, roadway structures, drivable paths, obstacles and so forth—and from there to control decisions introduces bias. The reason for this bias is that the sensing state might not be rich enough to reflect reality to its fullest and therefore the capacity of the system is constrained. In contrast, an E2E network skipping the sensing state step and instead mapping incoming videos directly to vehicle control decisions would not suffer from this bias of the “sensing state abstraction." On the other hand, the E2E approach will have a higher generalization error, and the approach advocated by the E2E proponents is to compensate for this error with huge amounts of data, which in turn necessitates a huge investment in compute, storage, and data engines.
To recap, the E2E approach – in the simplistic form being communicated to the public – is to define a system with zero bias while incrementally reducing variance through volumes of data for training the system with the purpose of gradually eliminating all “corner cases". In an engineered approach, on the other hand, the system starts with a built-in bias due to the abstraction of the sensing state and driving policy while (further) reducing variance through data fed into separate subsystems with a high-level fusion glue-code. The amount of data required for each subsystem is exponentially smaller than the amount of data required for a single monolithic system.
The devil is in the AI details
The story, however, is more delicate than the above dichotomy. Starting from the bias element, it’s not that E2E systems will have zero bias—since the neural network resides on an on-board computer in the car, its size is constrained by the available compute and memory. Therefore, the limited compute available in a car introduces bias. In addition, the approximation error of a well-engineered approach is not necessarily excessively large for several reasons. For one, Waymo is clear evidence that the bias of an engineered system is sufficiently small for building a safe autonomous car. Moreover, in a well-engineered system we can add a subsystem that skips some of the abstractions (e.g., the sensing state abstraction) and thus further reduce the bias in the overall system.
The variance element is also more nuanced. In an "engineered" system, the variance is reduced through abstractions (such as sensing state) as well as through the high-level fusion of multiple subsystems. In a pure E2E system, the variance should be reduced only through more and more data. But this process of reducing variance through a data pipeline deserves more scrutiny. Take the notion of mean time between failures (MTBF) and let's assume that failures are measured by critical interventions. Let's take MTBF as a measure of readiness of a self-driving vehicle to operate in an "eyes-off" manner. In Mobileye's engagement with car makers the MTBF target is 107 hours of driving. Just for reference, public data4 on Tesla's recent V12.3.6 version of FSD stands around 300 miles per critical intervention which amounts to an MTBF of roughly 10 hours – which is 6 orders of magnitude away from the target MTBF. Let's assume that somehow the MTBF has reached 106 hours and we wish merely to improve it by one order of magnitude in order to reach 107 hours. How much data would we need to collect? This is a question about the nature of the long tail of a distribution. To make things concrete, assume we have 1 million vehicles on the road driving one hour per day and the data in question is event-driven—i.e., when an intervention of the human driver occurs then a recording of some time around the event is being made and sent to the car maker for further training. An intervention event represents a "corner case" and the question of the long tail is how those corner cases are distributed. Consider the following scenario where B is the set of “bad” corner cases. An example of a heavy tail distribution is when B = {b_1,...,b_{1000}} and the probability of b_i to occur is 10-9 for every i. Even if we assume that when a corner case is discovered then we can somehow retrain the network and fix that corner case, without creating any new corner cases, we must knock off around 900 corner cases so that P(B) = 10-7. Because the MTBF is 106 then we encounter one corner case per day. It follows that we will need around 3 years to get this done. The point here is that no one knows how the long tail is structured - we gave one possible long tail scenario but in reality it could be worse or it could be better. As mentioned previously, while there is a precedent that the bias of an engineered system is sufficient for building a safe autonomous car (e.g. Waymo), there is still no precedent that reducing variance solely by a recurring data engine is sufficient for building a safe autonomous car.
It follows that to solely double-down on a data pipeline might be too risky. What else can be done in the E2E approach for reducing variance? To lead into it lets ask ourselves:
(i) Why does Tesla FSD have a sensing state in their display? The idea of an E2E system is you go from "photons to control" while skipping the need to build a sensing state. Are they doing that solely for the purpose of notifying the driver what the system “sees?" Or does it have a more tacit purpose?
(ii) Why has Tesla purchased 2,000 lidars5 from Luminar? Presumably for creating ground truth (GT) data for a supervised training. But why?
The two riddles are of course related.
Imagine an E2E network comprising of a backbone and two heads - one for outputting vehicle control and the other for outputting the sensing state. Such a network is still technically E2E (from photons to control) but also has a branch for sensing state. The sensing state branch needs to be trained in a supervised manner from GT data, hence the need for 2,000 lidars. The real question is whether the GT data can be created automatically without manual labeling. The answer is definitely yes because Mobileye does that. We have an "auto-GT" pipeline for training for sensing state. And, the reason why you would want a branch outputting the sensing state is not merely for displaying the sensing state to the driver. The real purpose of the sensing state branch is to reduce the variance (and more importantly the sample complexity of the system which is the amount of data needed for training) of the system through the "multi-tasking" principle. We addressed this back in 20166 and gave as an example an agricultural vehicle on the side of the road. The probability of observing a rare vehicle type somewhere in the image is much higher than the probability of observing such a vehicle immediately in front of us. Therefore, without a sensing state head (that detects the rare vehicle type on the shoulder even if it is not affecting the control of the host vehicle) one would need much more data in order to see such a vehicle immediately in front us, which affects the control of the host vehicle. What this comes to show is that the sensing state abstraction is important as it hints to the neural network that a good approach for giving correct control commands may need to understand the concept of vehicles and to detect all of the vehicles around us. Importantly, this abstraction is learned through supervised learning, using GT data which is created automatically (by a well-engineered offline system).
Another component of the popular E2E narrative is "no glue-code" in the system. No glue-code means no bugs being entered by careless engineers. But this too is a misconception. There is glue-code – not in the neural network but in the process of preparing the data for the E2E training. One clear example is the automatic creation of GT data. Elon Musk gave such an example – that of human drivers not respecting stop signs as they should and instead perform a rolling stop7. The rolling stop events had to be taken out of the training data so that the E2E system would not adopt bad behavior (as it is supposed to imitate humans). In other words, the glue-code (and bugs) are shifting from the system code to data curation code. Actually, it may be easier to detect bugs in system code (at least there are existing methodologies for that) than to detect bugs in data curation.
Don’t get into the way of analytic solutions
Finally, we would like to point out that when we have an analytical solution for a problem, it is certainly not better to use a purely E2E machine learning method. For example, the long multiplication exercise mentioned at the start of this blog highlights the fact that ChatGPT+, rightfully so, uses a good old calculator for the task and does not attempt to "learn" how to do long multiplication from a massive amount of data. In the driving policy stack (determining the actions the host vehicle should do and outputting the vehicle control commands) there are numerous analytical calculations. Knowing when to replace "learning" with analytical calculations is crucial for variance reduction but also for transparency, explainability and tuning8 (imitating humans is somewhat problematic because many of them are not good drivers).
Final words
AI is progressing at a remarkable pace. The revolution of foundation models of the like of ChatGPT began as a monolithic E2E model (back in 2022) whereas today it evolved into ChatGPT+9 which represents an engineered solution built on top of AI components including the base LLM, plugins for retrieval, code interpreter and image generation tools. There is much to be said about the claims that the future of AI is shifting10 from monolithic models to compound AI systems. We believe that this trend is even more important given the extremely high accuracy requirement for, and safety-critical aspect of, autonomous driving.
References:
1 Compound AI Systems
https://bair.berkeley.edu/blog/2024/02/18/compound-ai-systems/
2 the Alvinn project (Pomeraleau, 1989)
https://proceedings.neurips.cc/paper/1988/file/812b4ba287f5ee0bc9d43bbf5bbe87fb-Paper.pdf
3 Bias-variance tradeoff
https://en.wikipedia.org/wiki/Bias–variance_tradeoff
4 Public data on Tesla's recent V12.3.6 version of FSD
https://www.teslafsdtracker.com/home
5 Tesla purchased 2000 Lidars from Luminar
https://www.theverge.com/2024/5/7/24151497/tesla-lidar-bought-luminar-elon-musk-sensor-autonomous
6 On the Sample Complexity of End-to-end Training vs. Semantic Abstraction Training
https://arxiv.org/pdf/1604.06915
7 Human drivers not respecting stop signs as they should and instead perform a rolling stop
https://www.teslarati.com/tesla-rolling-stop-markey-blumenthal-letter-elon-musk/
8 Mobileye DXP as a novel approach
https://www.mobileye.com/opinion/mobileye-dxp-as-a-novel-approach/
9 ChatGPT+
https://openai.com/chatgpt/pricing
10 Future of AI is shifting from monolithic models to compound AI systems
https://bair.berkeley.edu/blog/2024/02/18/compound-ai-systems/
Share article
Related News


Press Contacts
Contact our PR team




