opinion
|
May 27, 2026
Driving The Long Tail
Efficient Scaling via Automatic Scenario Discovery
Prof. Shai Shalev-Shwartz and Prof. Amnon Shashua

Efficient Scaling via Automatic Scenario Discovery
Autonomous driving is often framed as a scaling problem: give a model enough data, compute, parameters, and time and eventually it will learn to drive.
This post reframes the scaling story for self-driving systems. Scaling data, model size, and compute is useful, but it is too slow when the target is ultra-low error on rare, safety-critical scenarios. The central idea is to separate failure discovery from failure resolution. That is where Meteor (an in-house tool developed at Mobileye) comes in: a data-scientist agent built around visual-language reasoning, retrieval, generation, and reproducibility testing.
Meteor’s job is not merely to find bad examples. Its job is to name the semantic failure class, retrieve or generate many variations of it, validate that the failure is reproducible, and then feed a concentrated learning signal back to the learner.
The bitter lesson meets the open road
Rich Sutton's well-known "Bitter Lesson" tells us that scaled, general methods eventually win. It's a tempting principle to apply to self-driving. Driving, after all, is the canonical open-world problem: unbounded scene variation, weather, geography, and the endless creativity of other road users. If the bitter lesson is right, the strategy is clear — learn everything from data. Avoid brittle, hand-designed interfaces. Embrace end-to-end learning. Pick up a general-purpose vision-language model and adapt it to driving. Scale the data, scale the compute, and let learning do the rest.
This is the scaling hypothesis, and it has become the implicit playbook across much of the field. In this post we want to argue that, while scaling is necessary, it is not sufficient — and more importantly, that the way we scale matters enormously. We'll lay out two problems that make pure scaling a slow path to safe driving, explain why they arise from a deep signal-to-noise issue, and then describe an approach we've been pursuing at Mobileye that attacks the problem directly: Scenario Boosting, powered by an agent we call Meteor.
Problem I: scaling has diminishing returns
The empirical scaling laws that govern modern deep learning - Chinchilla and its many cousins - take the rough form
with exponents \(\alpha_p, \alpha_s\) that are small - typically less than 0.1. This sounds innocuous until you ask what it costs to actually drive the loss down.
Suppose \(\alpha = 0.1\). Reducing loss from \(10^{-2}\) to \(10^{-6}\) - the kind of leap we need for safety-critical driving - requires roughly \(10^{40}\) times more parameters and data. That's not a scaling law. That's a wall. Scaling helps, but it is an extraordinarily slow path to ultra-low error.
Problem II: are we optimizing the right objective?
There's a second, subtler problem. Statistical learning minimizes expected loss. That objective is well-suited to ordinary applications, but it can be deeply misleading for safety.
Consider a fallen motorcycle rider, lying in the road, facing oncoming traffic. This is an extremely rare scenario - let's call its probability \(p \ll 1\). Suppose the system fails on this scenario systematically: any time the conditions roughly match, it gets it wrong.
From the expected-loss view, the contribution to the training objective is only \(O(p)\). The optimization pressure on this failure is tiny. The reported mean time between failures (MTBF) may even look acceptable. From the safety view, however, this is a disaster. The failure is reproducible: it persists across many variations of the same underlying scene. High MTBF is necessary, but it is not sufficient. We need to be safe across the space of scenarios, not just on average.
A "hay-in-a-haystack" problem
The standard metaphor for rare events is the needle in the haystack. For driving, it's the wrong metaphor.

Most driving data is uneventful. But the long tail is not a single needle - it is an enormous collection of rare-but-important scenarios. Each one individually has tiny probability, yet collectively the tail dominates the safety risk. It's hay hiding inside a much larger haystack, and you can't find it by squinting harder at the average example.
Why is scaling so slow?
Classical statistical learning often gives us scaling exponents of \(\alpha_s = 1\). So why do deep networks plod along at \(\alpha_s \approx 0.05\) to \(0.1\)?
We claim that the root cause is a poor signal-to-noise ratio (SnR) induced by two factors that are prevalent in self-driving:
- a long-tailed distribution combined with
- intrinsic uncertainty.
In a separate blog Why Learning from Data Gets Harder in the Tail we make this claim and prove it in a rigorous manner. For example, with a Zipfian distribution, \(p_i \propto i^{-\beta}\) with \(\beta > 1\), we show that \(\alpha_s = (\beta-1)/2\beta\). For \(\beta = 1.25\) this gives exactly \(\alpha_s = 0.1\) — the empirical ballpark.
SnR in self-driving
The theorem captures something the field already feels in practice. Driving has every ingredient for poor SnR:
- A long-tailed distribution of edge cases means most SGD updates come from common, weakly-informative scenarios.
- E2E supervision introduces intrinsic uncertainty: there are many valid ways to drive a given situation, but the data shows only one.
- Supervision is weak - we're "sucking supervision bits through a straw." Rare but important details may not even affect the chosen action, and credit assignment across components is poor.
- Shortcut learning is rampant. The classic example: deciding "stop vs. go" from the behavior of surrounding drivers rather than from the actual cause.
The conclusion is uncomfortable but unavoidable: efficient scaling requires increasing the signal-to-noise ratio, not just adding more of the same data.
Existing approaches implicitly improve SnR
Once you have the SnR lens, a lot of recent practice falls into place. Each of these techniques is, under the hood, a way to make the gradient signal less noisy:
- Adding structure and auxiliary tasks - perception heads, maps, occupancy, object tracking - provides stronger supervision and reduces ambiguity.
- Curriculum learning with pre-trained image backbones and foundation models reduces shortcut learning and representation collapse.
- Mining rare events from large fleets concentrates optimization on informative tail scenarios rather than boring ones.
- Photorealistic simulation lets us control the scenario distribution and densify rare events.
- Foundation and world models combine richer supervision, better priors, and a natural curriculum.
These all help. But they all attack SnR indirectly. The question is whether we can target it head-on.
Toward efficient scaling
Here is the main idea we want to propose:
Separate failure discovery from failure resolution.
SnR is poor because the signal from tail events is diluted by the noise from typical events. The way to fix this is to disentangle two distinct activities:
- Automatic discovery of meaningful scenario classes where the model fails.
- Focused resolution of those reproducible errors, with optimization pressure concentrated on the right inputs.
Done well, this dramatically increases the useful gradient signal on the cases that matter.
Inspiration from boosting
If this sounds familiar, it should: it is the spirit of Freund and Schapire's classic boosting, viewed through a modern lens.
SGD minimizes the expected loss, the MTBF-friendly objective:
Boosting instead targets the worst-case failure:
Crucially, the boosting process already disentangles discovery from resolution: collect failures, reweight the training distribution to amplify them, train a new model, repeat.
But classical boosting has two fatal limitations for driving
- Zero tolerance for noise. A single mislabeled example can derail the algorithm. In a world with real label uncertainty and automatic ground truth pipelines, this is a non-starter.
- Confined to the training set. For heavy-tailed problems, the training set may simply not contain enough variations of a rare scenario to learn from.
 Boosting on noisy data. The failures are due to spurios artifacts (which we call "black swans") or mislabeled ground truth (lower-right image). Boosting those failures can derail the detection algorithm.
Boosting on noisy data. The failures are due to spurios artifacts (which we call "black swans") or mislabeled ground truth (lower-right image). Boosting those failures can derail the detection algorithm.
We need a boosting-like objective that is robust to noise and able to reach beyond the training set.
A novel objective: scenario boosting
The fix is to take the max over scenarios rather than over individual examples, and to take an expectation within each scenario:
Here \(s\) is a semantic scenario - something like "motorcycle rider head-on to traffic" - and \(G(s)\) is a generator of variations of that scenario. The max identifies the worst reproducible failure class; the expectation inside makes it robust to non-reproducible noise.
"Max" for discovery, "expectation" for fixing.
This objective punishes only the failures that survive across many variations of a coherent semantic situation - exactly the failures that threaten safety.
What do we need to optimize it?
To make scenario boosting real, we need three ingredients:
- A semantic representation of scenarios.
- Automatic discovery of failure classes.
- A generator \(G(s)\) of scenario variations.
The slogan: discover, understand, and nail the spikes.
Scenario boosting as a two-player game
We can write the whole thing as a game:
At each round:
- SGD plays the learner, minimizing over \(\theta\).
- Meteor plays the data-scientist adversary - a Visual-Language-Reasoning Model whose job is to maximize over \(s\). It analyzes the learner's failures, proposes a scenario \(s\) in natural language (e.g., "motorcycle rider head-on to traffic") that explains a reproducible failure, then uses RAG and generative AI tools to sample variations \((x,y)\sim G(s)\) and verify that the error truly is reproducible.
A reproducible error, in this framework, is simply a scenario the VLRM agent can name.
Building the Meteor agent: data ingestion
The foundation of Meteor is a richly indexed driving corpus:
- Millions of hours of diverse driving data - different countries, vehicle installations, road types, weather conditions, lighting, and traffic cultures.
- VLM embeddings at multiple granularities: full video clips, individual frames, and individual objects.
- An elaborated prompt that asks a vision-language model to act as an expert data analyst. For each clip it produces a free-text description (around 120 words), structured scores with reasoning for visibility, rarity, dynamic scene complexity, and static scene complexity, and categorical classifications: day/dusk/night, weather, road structure (junction, roundabout, number of lanes), road quality, and so on.
The end result is that every piece of driving data is represented as free text, a vector of structured properties, and an embedding - searchable from any of those angles.
Building the Meteor agent: semantic search
On top of that index, Meteor offers fast retrieval:
- Approximate nearest-neighbor search over the embedding space (Pinecone).
- Combined text + embedding search (ElasticSearch).
- Sliders to constrain search by structured properties - "night," "rarity > 6," and so on.
- An API exposed to the agent via MCP, plus a web GUI for human debugging.
The agent has, in effect, a database of the world's driving and a vocabulary to query it.
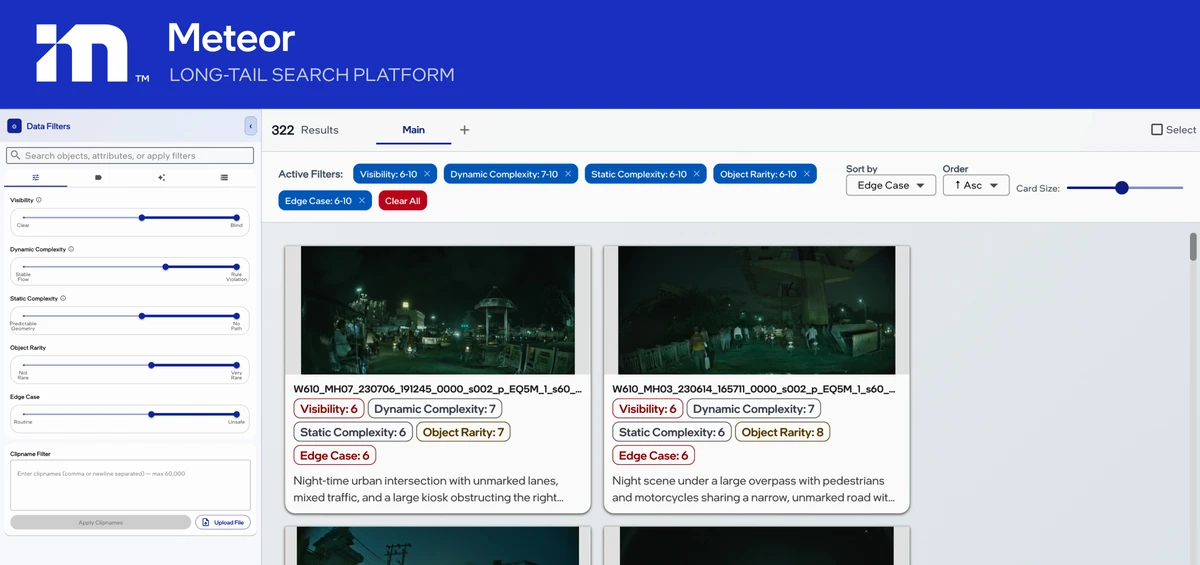
Meteor in action - step I: the analyst
The agent's first job is to be an analyst. For each failure of the current model \(\theta\) on the training set, it forms a hypothesis about the root cause and decides whether the failure is reproducible.
A non-reproducible failure
Sometimes a failure is just bad luck - a single odd frame that won't survive resampling.


A reproducible failure
Other failures hint at something structural. Here's an example hypothesis the analyst might propose:
The model appears to require canonical head-torso-leg evidence; visible human mass is under-ranked when legs, head, or other independent body parts are hidden by foreground bands, bulky clothing, or truncation.


This is the kind of failure mode that, if real, will reproduce across many otherwise unrelated images. That's exactly what we want to confirm.
Meteor in action - step II: queries
To test the hypothesis, the agent proposes a set of database queries that should retrieve more instances of the same underlying failure class:
- Missing body parts
- Partial pedestrian body
- Torso visible, no legs
- Feet hidden by car hood
- Draped clothing person
Each query is a different angle on the same conjectured scenario.
Meteor in action - step III: retrieval and generation
Now the agent assembles \(G(s)\):
- Run the queries against the database.
- Re-rank the results.
- Choose the most informative ones.
- Evaluate \(\theta\) on those results to check for reproducibility - if the loss on \(G(s)\) is significantly worse than the average loss, the hypothesis is accepted.
- Feed samples from \(G(s)\) to the learner.
This is the closed loop: a named scenario produces a focused training set, which produces a focused gradient signal, which actually moves the model on the cases that matter.
Samples from \(G(s)\)

Beyond real data
The real-world database is enormous, but even it has holes. Some scenarios are so rare that we'd struggle to find enough variations. For these we turn to generation.
Real examples of the kinds of road debris that matter:

Generating photo-realistic videos
When real footage runs out, we generate variations directly:
The same agent that names a scenario can describe it well enough for a generative model to produce more of it, on demand.
The generative model supports scene property variation, producing identical scenarios under different environmental conditions such as nighttime, rain, and snow.
What else lives in the tail?
A small gallery of the kinds of scenarios Meteor surfaces - each one rare, each one safety-relevant, each one a named class that can be drilled into and learned:
Pedestrians spilling out of a bus
Loose trash that turns into an obstacle
Drivable terrain that looks like a hazard, or vice versa
An airplane on the road - yes, really
Double parking, in all its inventive forms
Each of these is a worked example of the broader thesis: the long tail is huge, but it is enumerable once you have the right semantic tools to point at it.
Summary
To bring it all together:
- Heavy tail + uncertainty ⇒ poor SnR ⇒ scaling that is far too slow for safety-critical driving.
- Efficient scaling requires separating failure discovery from failure resolution - pushing optimization pressure onto the cases that actually matter.
- Scenario Boosting formalizes this: a max over named, semantic scenarios with an expectation over their variations.
- Meteor is the agent that makes Scenario Boosting practical - automatically discovering, validating, and generating the rare safety scenarios the model needs to see.
The bitter lesson isn't wrong. But for safety-critical systems, the way you scale matters as much as how much you scale. Discover the spikes, name them, generate around them, and learn from them - that's how the long tail gets driven.
Share article
Related News


Press Contacts
Contact our PR team




